Understanding how scientists collaborate is key to improving research, but much of that collaboration is informal and buried in unstructured text. In our new article published in Applied Network Science, we show how Large Language Models (LLMs) can uncover these hidden networks—retrieving both inter-team collaborations and intra-team task allocations from free-form text with high accuracy.
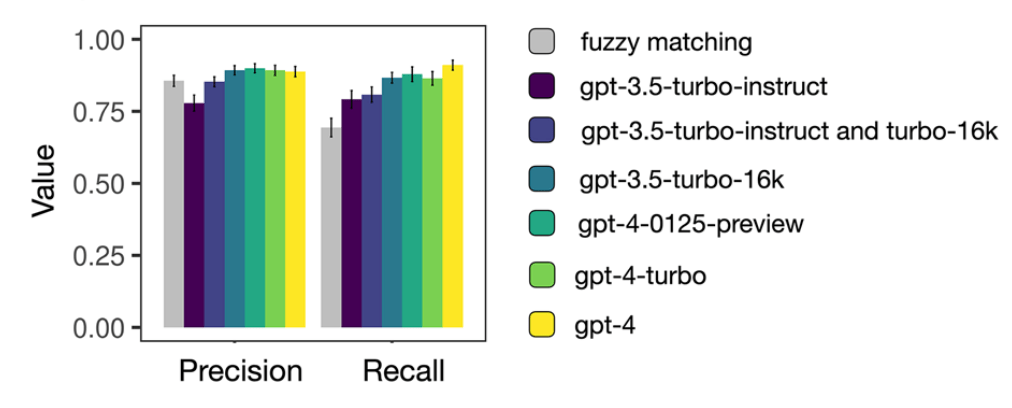
Using the digital lab notebooks of over 2,000 iGEM synthetic biology teams, we developed a semi-automated pipeline that outperforms traditional fuzzy matching approaches. GPT-4, in particular, achieved recall rates as high as 0.91, and the reconstructed networks preserved core structural properties such as centrality, assortativity, and nestedness. Our results suggest that LLMs offer a scalable and flexible solution for curating rich collaboration data at scale, with applications well beyond the scientific domain.
📖 Read the article: https://doi.org/10.1007/s41109-024-00658-8
📂 Data and code: GitHub Repository
